
Неправильная постановка вопроса
Фраза можно ли доверять AI-коду звучит так, будто код можно оценивать отдельно от среды. На практике это не так. Один и тот же фрагмент может быть безопасной заготовкой в одном процессе и опасной миной в другом. Код не существует сам по себе. Он входит в систему с тестами, логикой владения, доменными ограничениями, историей изменений и будущей поддержкой. Именно это и определяет допустимость.
Поэтому код, который просто запускается, ещё не является качественным. Компиляция не доказывает сохранность инвариантов, а зелёные тесты не гарантируют, что тесты вообще проверяли важное. Этот сдвиг полезен сам по себе: разговор о доверии нужно выводить из плоскости вера в модель в плоскость инженерной дисциплины.
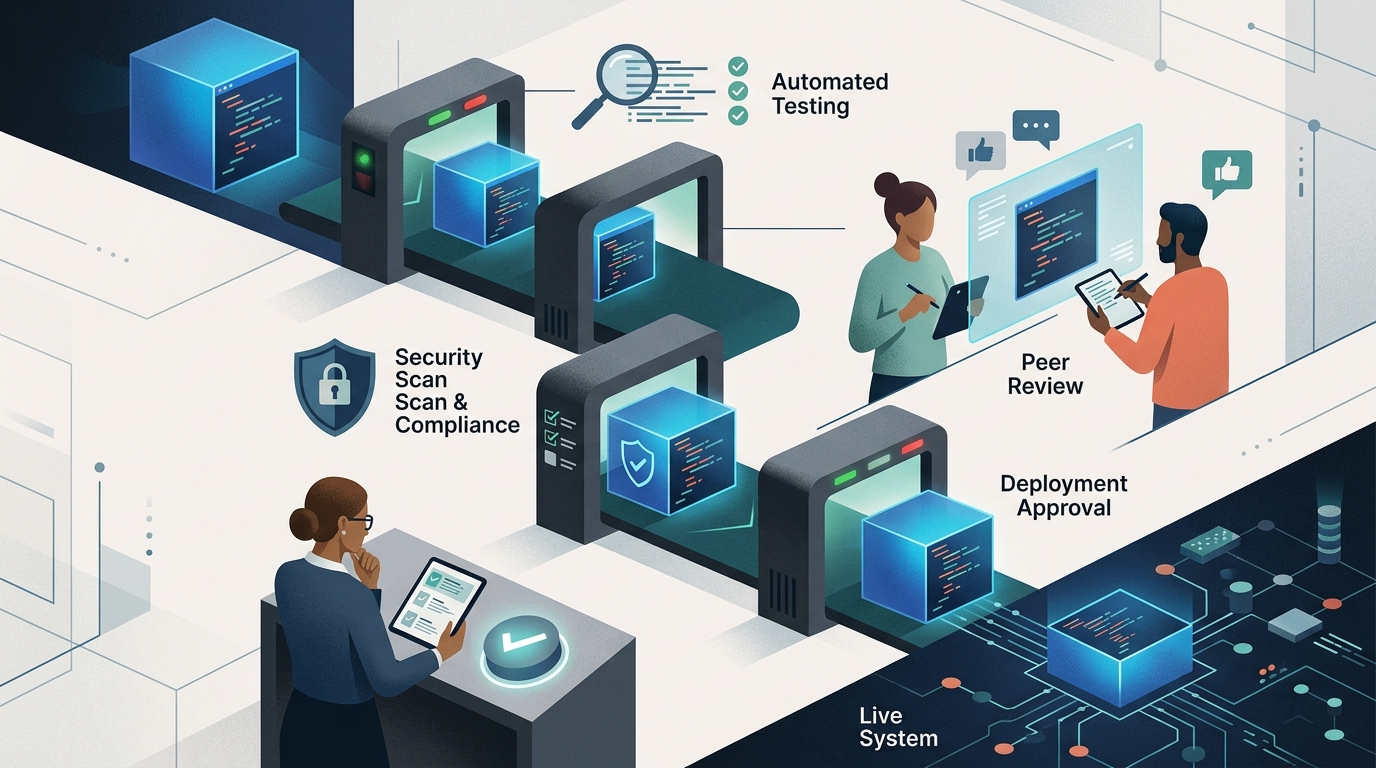
Где AI-код уже допустим
Есть класс задач, где AI-код действительно удобен и сравнительно безопасен. Стандартный boilerplate, типовые интеграции, тестовые каркасы, локальные изменения в понятном модуле, небольшие рефакторинги под уже существующий набор проверок. Здесь ценность модели не в том, что она умнее команды, а в том, что она снимает механическую нагрузку и экономит время на рутинной сборке.
Критерий выбора здесь простой: изменение должно жить в хорошо наблюдаемом контуре. Если можно быстро прогнать тесты, локально поднять систему, проверить поведение на границах и увидеть, что именно поменялось, AI-код вполне может входить в нормальный производственный поток. Не как исключение, а как ещё один способ подготовить черновик изменения.

Где риск резко растёт
Риск резко растёт там, где ошибка дорога, а проверка неполна. Безопасность, конкурентный доступ к состоянию, производительность под нагрузкой, протоколы повторных запросов, неочевидные крайние случаи, сложная доменная логика. В этих участках AI особенно коварен, потому что часто предлагает чистое и убедительное решение, которое нарушает не синтаксис, а смысл. Например, исправляет endpoint и незаметно ломает семантику повторной доставки сообщений.
Анти-паттерн здесь почти всегда одинаков. Senior просмотрел diff, тесты зелёные, код выглядит аккуратно, значит можно выпускать. Это слишком слабый стандарт. Если команда не проверила предпосылки, не задала сценарии отказа и не понимает, что именно стало новым обязательством на поддержку, AI-код оказывается не ускорением, а способом быстрее пронести ошибку через процесс.

Что делает процесс безопасным
Безопасный процесс состоит из нескольких скучных вещей, которые плохо смотрятся в демо, но отлично работают в проде. Тесты до слияния, review не только текста diff, но и допущений, ограничение областей, где AI допустим по умолчанию, и чёткое владение изменением. Последний пункт особенно важен: кто-то в команде должен принять этот код как свой и быть готовым объяснить его через неделю, месяц и полгода.
Это и есть настоящая граница доверия. Не модель заслужила доверие, а команда построила режим, в котором риск контролируется. Если такого режима нет, вопрос можно не обсуждать: выпускать AI-код в боевую систему рано. Если режим есть, AI-код становится обычной частью инженерной практики — но без права списывать баг на инструмент.
Вывод
Доверять нужно не самому AI-коду, а процессу, который делает его допустимым для боевой системы. Если у команды нет тестов, внятного ревью и закреплённой ответственности за изменение, такой код не должен доходить до продакшена.


