
Почему правдоподобность опаснее грубости
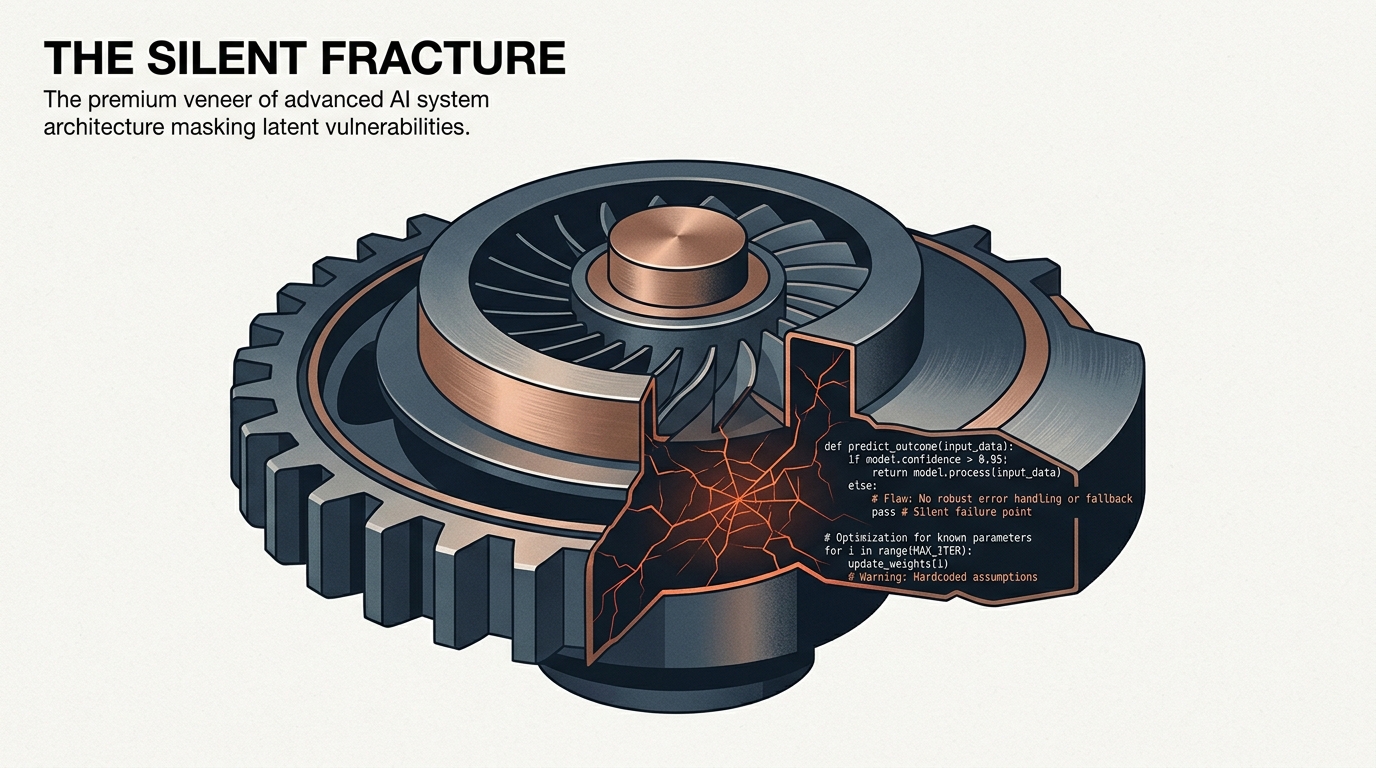
Когда код выглядит плохо, команда естественно включает защитную реакцию. Когда код выглядит уверенно, защита ослабевает. Это и есть главная когнитивная ловушка AI-генерации. Модель хорошо подражает форме зрелого решения: даёт чистые функции, знакомые абстракции, понятные названия, ровную структуру. Визуально это считывается как компетентность, хотя по сути код может опираться на неверную картину мира.
Сравнение ugly but correct и clean but wrong здесь особенно полезно. Неловкое, но точное решение часто заставляет ревьюера задавать вопросы. Гладкое и элегантное решение вызывает меньше трения и потому легче проходит дальше. В реальном производстве именно это делает AI-код коварным: он редко кричит о своей проблеме, он вежливо маскирует её под хороший вкус.
Какие ошибки прячутся в гладком коде
Чаще всего внутри такого кода сидят не синтаксические, а смысловые ошибки. Неверные допущения о бизнес-логике, потерянные крайние случаи, слишком смелые обобщения, неверная работа с состоянием, ошибки интеграционных контрактов, тихая деградация производительности. Например, модель красиво переписывает кеширование, но нарушает согласованность данных. Или оптимизирует запрос, не заметив, что ломает устойчивость пагинации на реальном потоке обновлений.
Плохая новость в том, что многие из этих дефектов не всплывают в локальном happy path. Хорошая — у них есть общая черта: почти всегда где-то спрятана ложная универсальность. Если решение выглядит умнее задачи, если абстракция шире реальной потребности, если код обобщает там, где домен требует точности, стоит не восхищаться, а насторожиться.

Почему обычная проверка это пропускает
Обычный review слишком часто остаётся визуальной процедурой. Проверяется стиль, читаемость, соответствие паттернам, локальная аккуратность. Но AI-код ломается не там. Он ломается в невысказанных гипотезах. Ревьюер видит знакомую форму и перестаёт спорить с содержанием. Чем сильнее код похож на старший уровень, тем меньше шансов, что его разберут по-настоящему критично.
Отдельная проблема в том, что ревью текста diff подменяет ревью поведения системы. Если проверка не включает сценарии отказа, влияние на соседние модули и вопрос что именно мы считаем инвариантом, команда смотрит не на то. Это не дефект AI как такового, а усиление старой человеческой слабости: мы переоцениваем убедительную форму.
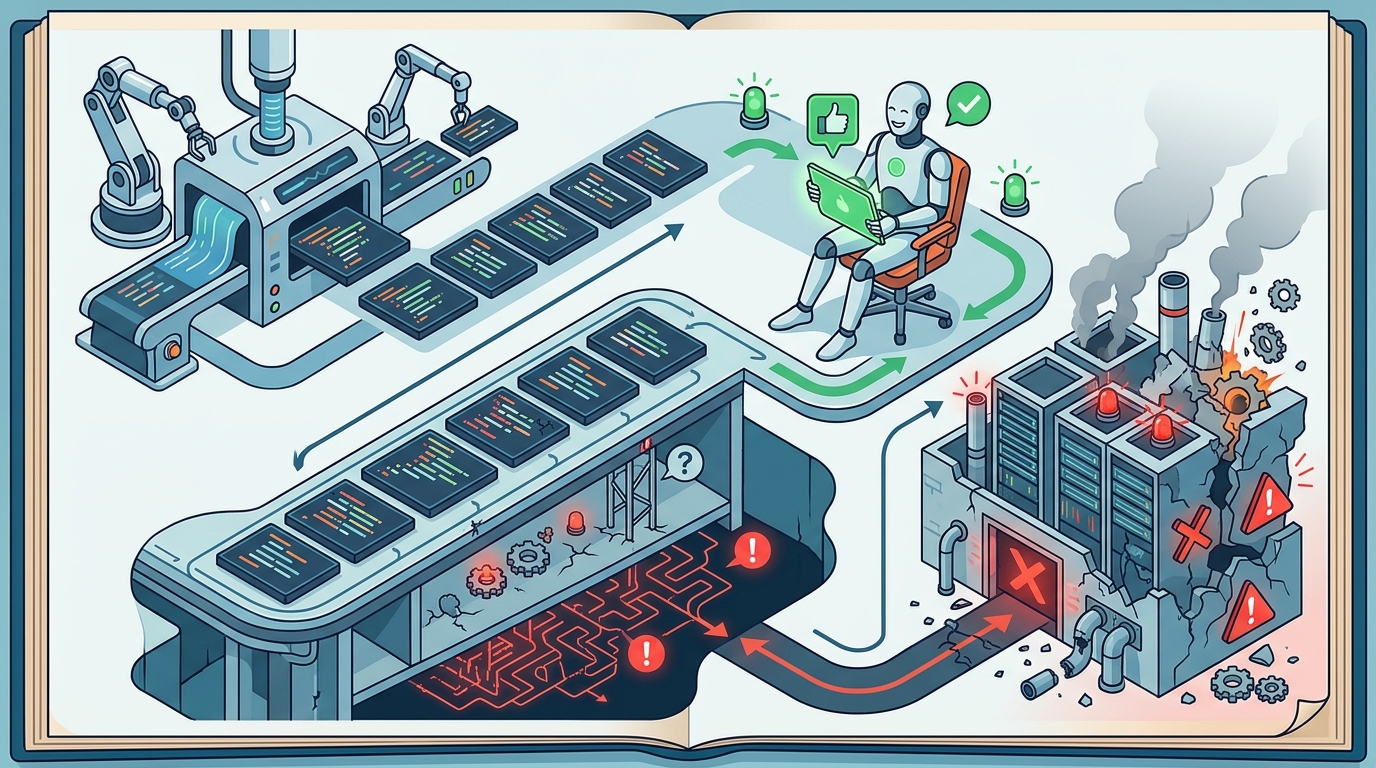
Как проверять по-настоящему
Рабочий review начинается с вопросов не к коду, а к модели мира внутри него. Какие допущения сделаны? Где решение полагается на порядок событий? Какие крайние случаи явно не покрыты? Что произойдёт при повторном вызове, пустом наборе данных, конфликте состояний, сетевом шуме или частичном отказе соседнего сервиса? Такие вопросы звучат приземлённо, но именно они отличают надёжную проверку от поверхностной эстетики.
Практический критерий прост: если после review команда лучше понимает поведение системы, значит проверка была полезной. Если после review все только согласились, что код красивый и аккуратный, скорее всего, вы проверили не то. Для AI-кода это особенно важно, потому что его главная сила и его главный риск совпадают: он умеет быть убедительным.
Вывод
Главная проблема AI-кода в том, что он часто выглядит убедительно раньше, чем оказывается правильным. Поэтому хороший ревью-процесс должен проверять не гладкость диффа, а предпосылки, граничные случаи и поведение системы после изменения.


