
Почему спор стал практическим
Пока AI жил в режиме демонстраций, разговор о закрытых и открытых моделях легко сводился к лозунгам. Но как только модели начали входить в продукты и внутренние процессы, выбор стал приземлённым. У него появились последствия: latency, data residency, комплаенс, цена на масштабе, зависимость от поставщика, сложность обновления и даже скорость экспериментов внутри команды.
Именно поэтому главный вопрос звучит уже не какая модель лучше вообще, а какая форма зависимости приемлема для конкретной системы. Стартап, который бежит за временем вывода на рынок, и компания с жёсткими требованиями к данным решают разные задачи. Пытаться мерить их одной линейкой бессмысленно. На практике это спор не о вкусах, а о режиме управления риском.
Ссылки на источники
Где каждый из подходов объективно выигрывает
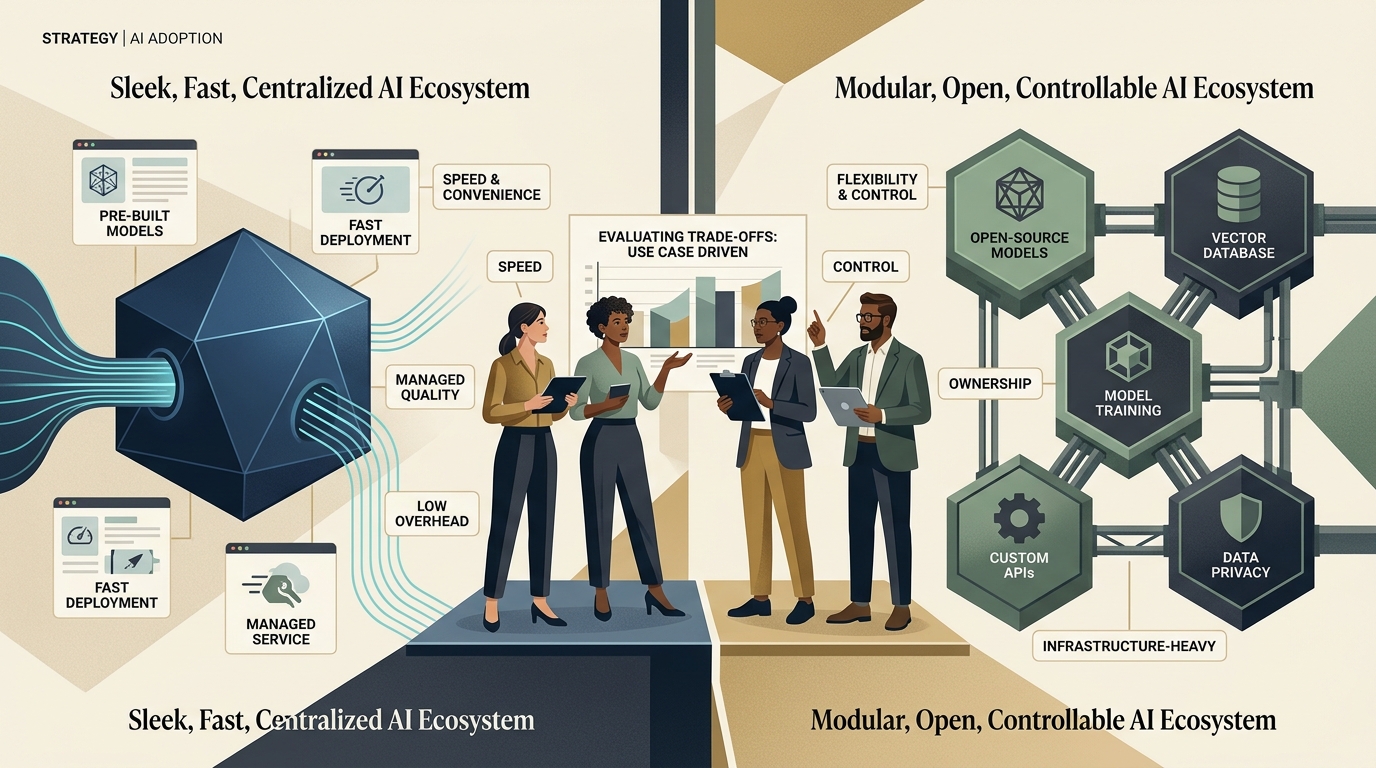
У закрытых моделей есть сильные стороны, которые не стоит романтично игнорировать. Быстрый доступ к state-of-the-art, удобный managed-слой, высокая скорость подключения новых возможностей, часто более сильное поведение на сложных задачах общего назначения. Если команде нужно быстро проверить продуктовую гипотезу и не строить вокруг модели отдельную операционную платформу, закрытый API может быть самым рациональным решением.
У open-source выигрыши другие. Контроль над развертыванием, возможность оставить чувствительные данные внутри собственного контура, настройка под узкий домен, более предсказуемая стоимость на масштабе, независимость от изменений чужого продукта. Но здесь есть честный trade-off: контроль не бывает бесплатным. Чем больше инфраструктуры вы берёте на себя, тем больше платите за эксплуатацию, обновления и качество сервиса вокруг модели.

Где команды ошибаются в сравнении
Самая частая ошибка — смотреть только на benchmark и путать лабораторную силу модели с полезностью в реальном контуре. Для одного сценария важнее глубокое рассуждение, для другого — приватность, стабильная цена и короткий отклик. Сравнение closed API для сложного reasoning и локальной модели для массовых внутренних преобразований бессмысленно без контекста, потому что это разные задачи и разные режимы эксплуатации.
Вторая ошибка — считать, что можно запустить равно можно надёжно использовать. Многие команды выбирают open-source ради свободы, а потом тонут в поддержке. Другие выбирают закрытое решение ради качества и не замечают, как критическая часть продукта переезжает в чужую операционную систему. Поэтому зрелый вывод обычно не бинарный. Побеждает не одна сторона, а архитектурная гибкость: умение держать гибрид, маршрутизировать запросы и не строить продукт так, будто одна модель обязана решить всё.
Ссылки на источники
Вывод
У закрытых и открытых моделей нет одного победителя на все случаи. Выигрывает та архитектура, которая лучше укладывается в ваши требования к качеству, приватности, стоимости и управляемости, а для многих команд это означает гибридный стек, а не идеологический выбор лагеря.


