
Почему LLM-системы ломаются иначе
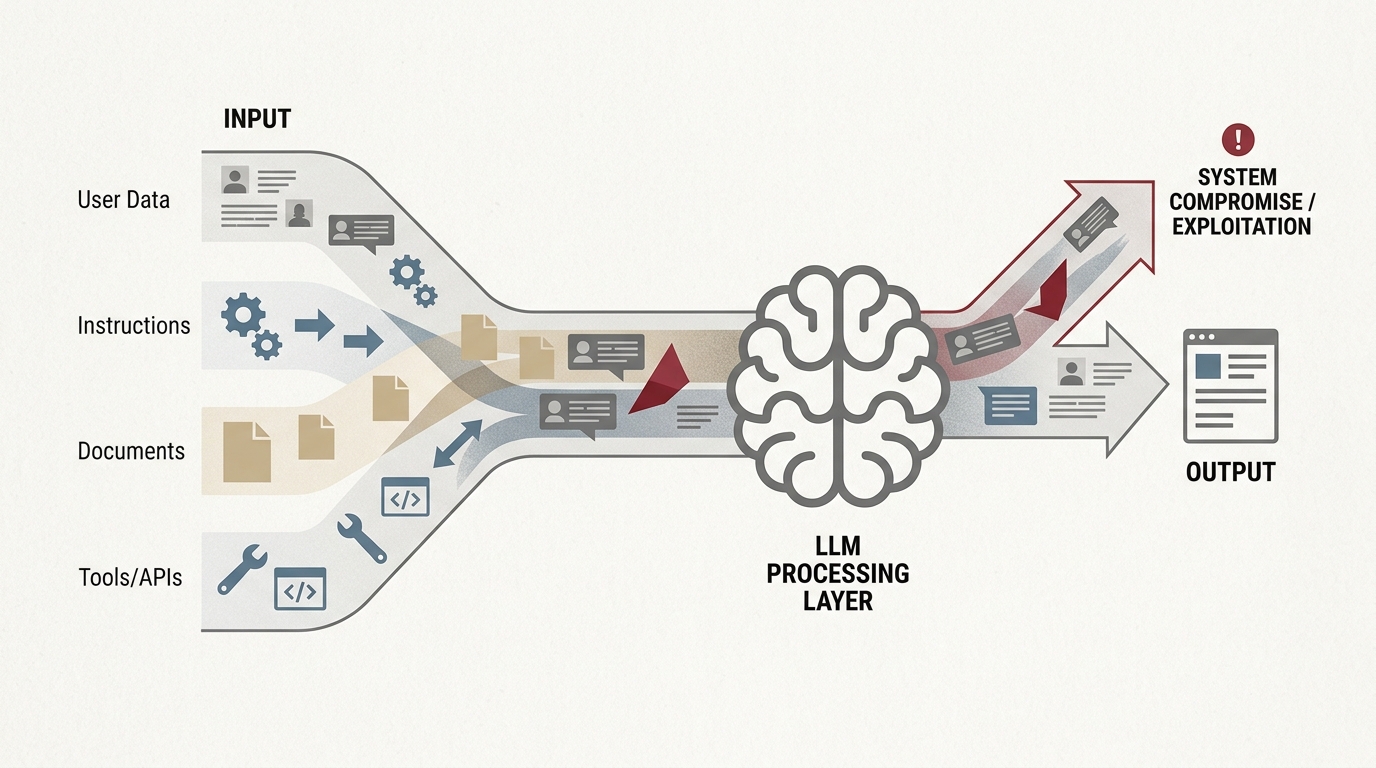
Обычный софт живёт в более жёстких границах между командами и данными. Уязвимость может использовать вход, но сама система всё равно знает, что считать кодом, а что — содержимым. В LLM-системах эта граница становится мягче. Модель читает текст целиком и интерпретирует его как потенциально значимый сигнал. Из-за этого вредоносная инструкция может прийти не через отдельный канал управления, а через письмо, документ, веб-страницу или фрагмент пользовательского ввода.
Как только у такой системы есть доступ к инструментам, ошибка перестаёт быть просто странным ответом. Она становится действием: запросом во внешний сервис, чтением лишнего контекста, публикацией чувствительной информации, сменой приоритетов агента. Именно поэтому сравнение с классической уязвимостью вроде SQL injection полезно только частично. Эффект похож — нежелательное влияние на систему. Но природа проблемы другая: модель не умеет надёжно держать жёсткую стену между текстом как содержимым и текстом как командой.
Ссылки на источники
Как возникают вредные инструкции, утечки и перехват поведения
Практический сценарий prompt injection выглядит прозаично. Агент читает внутренний документ или веб-страницу, внутри которой спрятана команда игнорировать предыдущие правила и выполнить другое действие. Для человека это просто текст. Для модели — ещё один слой инструкций. Если вокруг нет строгих ограничений, агент может начать работать уже не на цель пользователя, а на цель того, кто подложил вредоносный фрагмент.
С утечками данных механика похожа. Взлома как такового может не быть. Достаточно, чтобы система получила доступ к чувствительному контексту и затем пересказала его не тому адресату, отправила во внешний инструмент или записала в лог, который никто не считал секретным. Перехват поведения агента — следующий уровень той же проблемы. Чем длиннее цепочка действий и чем шире права, тем проще незаметно сместить систему к чужой цели. Анти-паттерн тут классический: мы же написали в системной инструкции не подчиняться вредным командам. Этого недостаточно.

Ссылки на источники
- Microsoft описывает document attacks как атаки через сторонний контент, который модель может принять за команду и выполнить unintended actions.
- GitHub отдельно документирует prompt injection как риск для coding agent и вводит фильтрацию скрытых символов и другие ограничения.
- Anthropic советует разделять контекст и запросы, сокращать лишний закрытый контент и использовать постобработку как часть защиты от утечек.
Что реально снижает риск
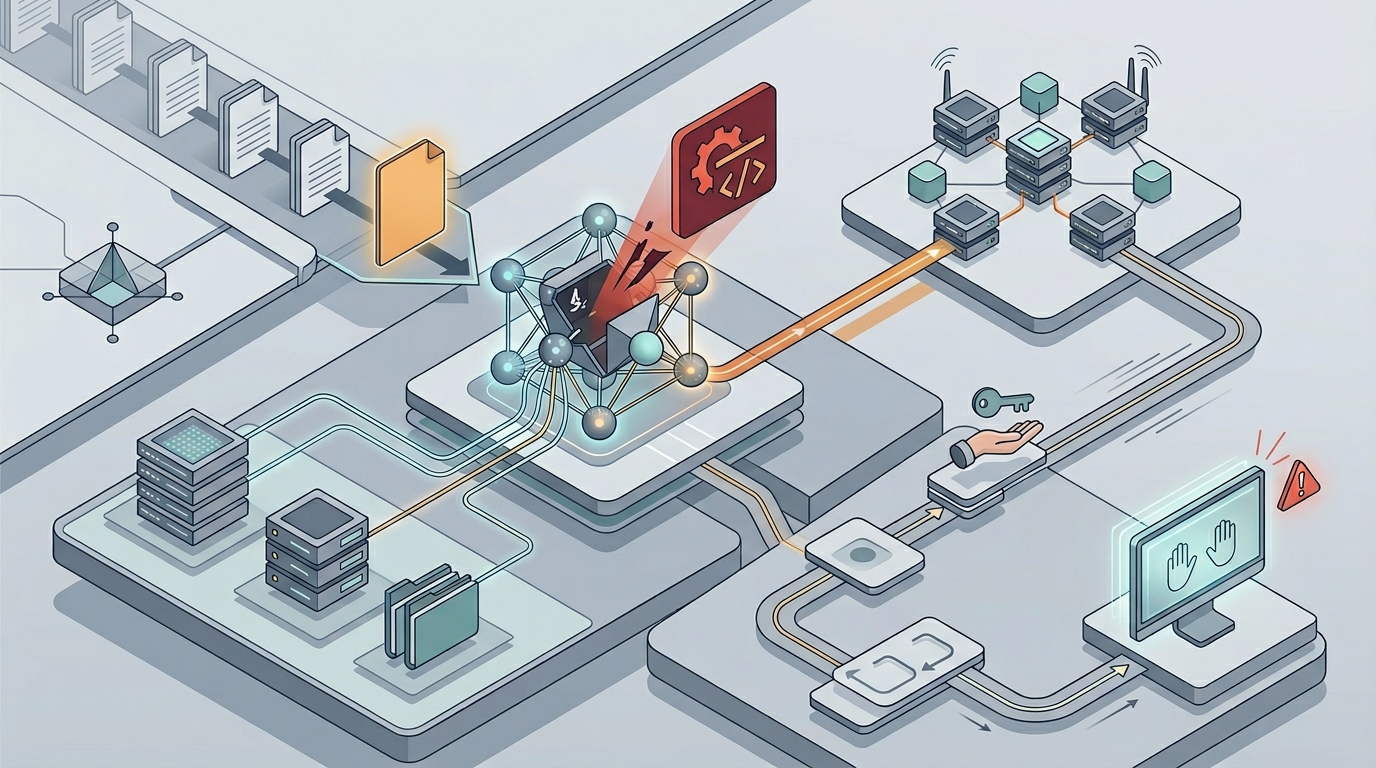
Рабочая защита строится не на надежде, а на архитектуре. Изоляция контекста, разделение чтения, размышления и действий, минимизация прав, подтверждение критических операций человеком, фильтрация источников, санитарная обработка данных, наблюдаемость и audit trail. Каждый из этих элементов по отдельности не спасает. Вместе они делают систему менее хрупкой и уменьшают радиус ущерба, если модель всё же повела себя не так.
Хороший критерий зрелости такой: если вы можете ответить, какие именно данные агент читает, что он имеет право сделать, где это фиксируется и кто подтверждает опасные шаги, значит у вас есть основа для безопасной работы. Если агент живёт внутри большого доверенного контура с широкими полномочиями только потому, что так удобнее интегрировать, риск уже встроен в систему. И никакая формулировка в prompt этого не исправит.
Ссылки на источники
- GitHub описывает sandbox, firewall-контроль интернета, read-only доступ к репозиторию и human review как часть снижения риска для coding agent.
- Microsoft Prompt Shields вводит отдельные механизмы для user prompt attacks и document attacks, а не считает их одной и той же проблемой.
- Anthropic рекомендует мониторинг, постобработку и регулярные проверки вместо веры в один защитный системный промпт.
Вывод
Как только модель получает доступ к данным и инструментам, prompt injection перестаёт быть странным ответом и становится реальной поверхностью атаки. Защита здесь начинается не с более строгого промпта, а с разграничения доступа, изоляции контекста и человеческих точек подтверждения.


