
Почему RAG так быстро стал стандартом
RAG быстро стал популярным, потому что у него очень удобная история продажи. Есть модель, есть ваши документы, между ними кладётся retrieval, и AI начинает говорить на основе собственного корпуса знаний. Для большого числа команд это выглядело как короткий мост между универсальной моделью и внутренними данными. Концепция достаточно понятная, чтобы её легко было принять и руководителю, и инженеру.
Но именно эта простота и сделала RAG переиспользуемым шаблоном. Команды начали тянуть его туда, где сам вопрос не является документным по своей природе. Как только retrieval превращается в замену размышлению о структуре данных, начинается подмена архитектуры модным паттерном. И это видно очень быстро: ответ становится длиннее, а точнее — нет.
Где он действительно хорош
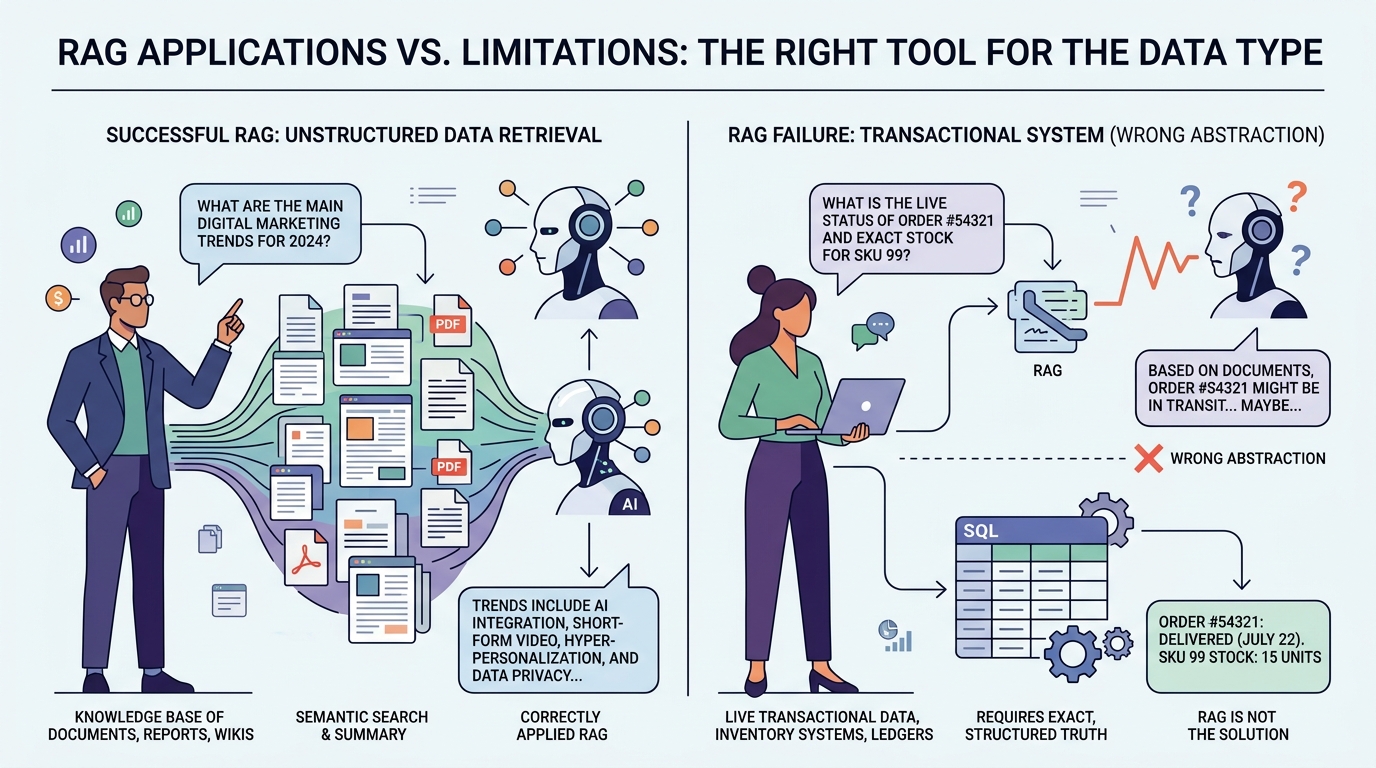
RAG силён в сценариях, где задача и правда связана с поиском по большому корпусу текста. Внутренняя документация, Q&A по политикам, помощники по знаниям, сценарии, где важна актуальность источника, а не запоминание фактов моделью. Здесь retrieval работает как grounding: он подсовывает системе релевантный контекст и тем самым делает ответ более связанным с реальными документами, а не с общим знанием модели.
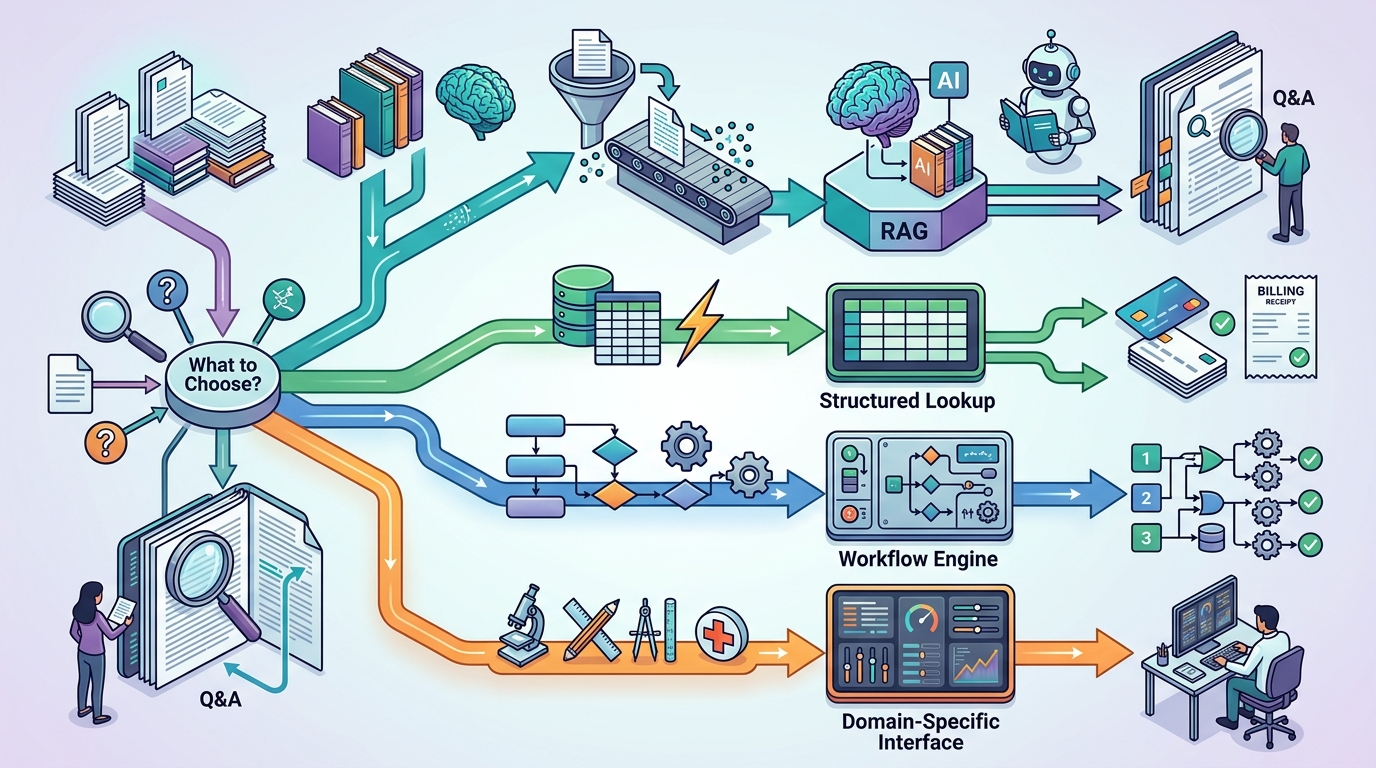
Практический критерий выбора здесь простой: если у вас действительно есть текстовый корпус, а пользователю нужен ответ с опорой на него, RAG — хороший кандидат. Если же под словом данные скрывается скорее набор таблиц, статусов, транзакций и жёстких бизнес-правил, нужно быть осторожнее. Там retrieval по документам может создавать ощущение знания, не давая точной истины.

Ссылки на источники
- Microsoft описывает хорошие RAG-системы через качественную ingestion-подготовку, chunking, индексы, post-retrieval filtering и обновление базы.
- OpenAI file search документирует встроенные retrieval practices: query rewriting, параллельные поиски, keyword + semantic search и reranking.
- AWS также описывает RAG как способ использовать внешние источники знаний для более точных и актуальных ответов.
Где RAG переоценён
Проблемы начинаются в задачах, где нужен не релевантный фрагмент текста, а точное состояние системы. Ответы по биллингу, доступам, заказам, лимитам, историям операций. В таких сценариях retrieval по разрозненным документам легко приносит шум, устаревшую информацию или противоречащие друг другу источники. Здесь лучше работают structured retrieval, прямые запросы в систему истины или workflow-движок, а не болтливый слой над документами.
Анти-паттерн выглядит знакомо: команда индексирует всё подряд, удивляется неточным ответам и думает, что проблема в недостаточно сильной модели. На деле часто ломается сама абстракция. Если задача требует точности, traceability и контролируемого ответа, продукту может быть нужнее специализированный интерфейс или детерминированная логика, чем ещё одна RAG-надстройка.
Ссылки на источники
Вывод
RAG полезен, когда вопрос действительно опирается на большой текстовый корпус и свежие источники знаний. Если истина живёт в структурированных данных, бизнес-правилах или точных вычислениях, попытка решить всё через retrieval только маскирует архитектурную ошибку.


