
Почему тема вернулась
Пока API казались почти безграничным источником интеллекта, локальные модели выглядели либо хобби, либо компромиссом. Ситуация изменилась, когда зависимость от внешнего поставщика стала стратегическим вопросом. Для одних это упирается в границы данных, для других — в предсказуемость расходов, для третьих — в нежелание строить продукт так, будто ключевой слой системы всегда находится под контролем чужой компании.
Именно поэтому разговор о локальных моделях сегодня сильнее связан с контролем, чем с энтузиазмом вокруг self-hosting. Команде важно не просто запустить модель на своей машине. Ей важно понимать, где проходит граница ответственности, что будет с задержкой, как считать полную стоимость владения и какие части контура стоит оставить внутри собственной инфраструктуры.
Где локальные модели реально сильны
Лучшие сценарии у локальных моделей обычно не выглядят героически. Это внутренний поиск по закрытому коду, локальная классификация, on-device суммаризация, частые преобразования текста, доменные помощники внутри корпоративного контура, сценарии с чувствительными данными или нестабильной связью. Здесь решает не абсолютный максимум качества, а сочетание приватности, короткого отклика и контроля над средой исполнения.
Полезный критерий выбора такой: чем уже и повторяемее задача, тем выше шансы, что локальный запуск окажется рациональным. Анти-паттерн начинается там, где маленькая команда пытается развернуть полный локальный стек просто ради независимости. Если эксплуатация, обновления и качество начинают съедать весь выигрыш, контроль превращается в дорогую иллюзию.

Ссылки на источники
- Google AI Edge прямо описывает on-device LLM inference для генерации текста, извлечения информации и суммаризации без вывода вычислений в облако.
- Gemma docs и интеграции для web подтверждают сценарии запуска лёгких моделей на устройстве и в браузере.
- Windows AI / Phi Silica показывает, что on-device LLM-контур поддерживается и на стороне платформенного вендора, хотя доступ к нему ограничен.
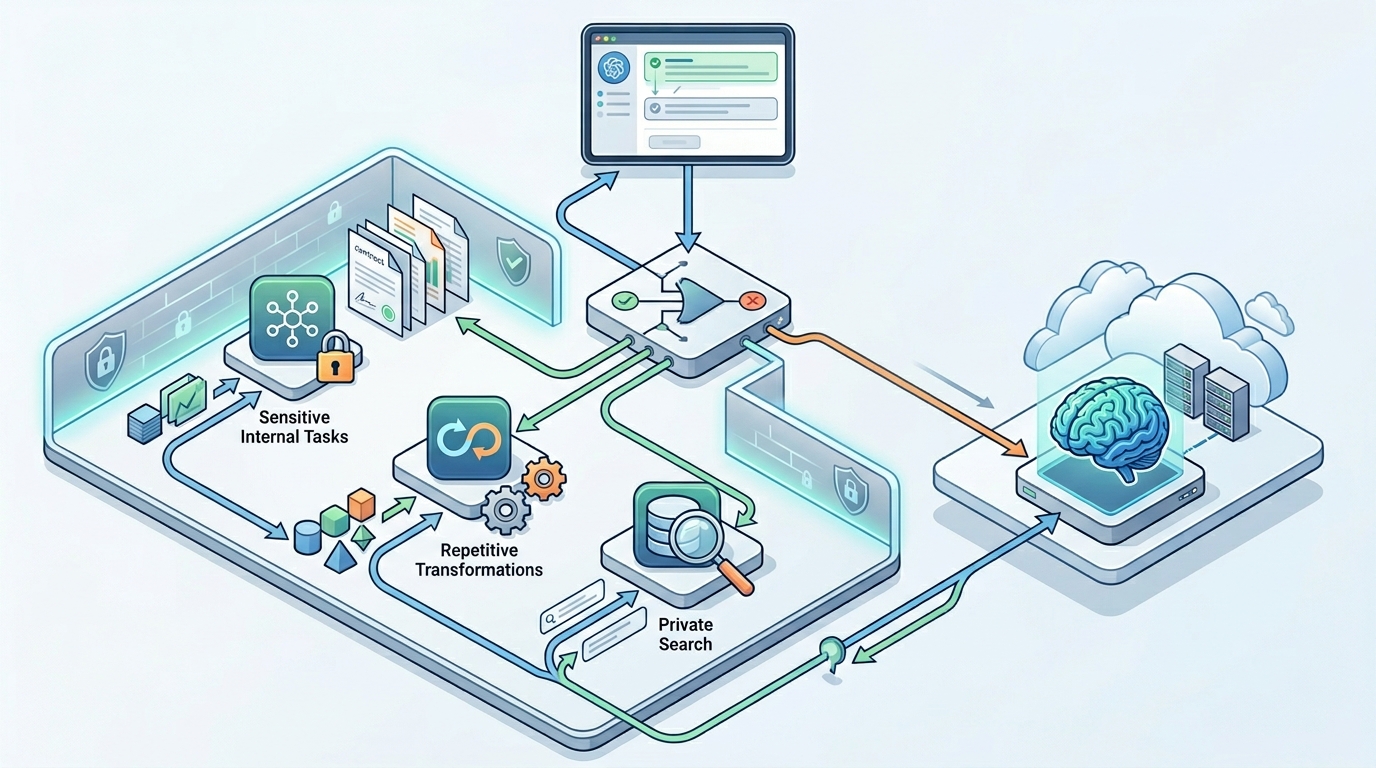
Где они проигрывают и почему побеждает гибрид
Локальные модели всё ещё чаще проигрывают там, где нужен сильный reasoning общего назначения, большой контекст или быстрый доступ к передовым возможностям без собственного операционного слоя. Запустить модель на ноутбуке не значит получить production-ready решение. Между демонстрацией и надёжным продуктом лежат вопросы инфраструктуры, наблюдаемости, обновлений и качества сервиса вокруг модели.
Поэтому в реальности часто побеждает гибрид. Чувствительные и частые сценарии остаются локальными, а редкие и сложные запросы уезжают во внешний сервис. Такой подход скучнее идеологических лозунгов, но полезнее в эксплуатации. Он позволяет не делать из локальной модели культ и не превращать внешний API в единственный фундамент всего продукта.
Ссылки на источники
Вывод
Локальные модели возвращаются там, где важнее контроль над данными, предсказуемая нагрузка и близость вычисления к пользователю, чем максимальное качество любой ценой. Они не заменяют облако целиком, а дают команде способ точнее выбрать, что держать у себя, а что отдавать наружу.


